What I originally took to be a quest for personal information management (PIM) nirvana, I now realize is in fact a perpetual cycle of personal information management samsara: the constant death of old tools and birth of new. As someone who loves building tools, I suppose this is a good thing.
Before introducing the newest incarnation in this cycle, let me give a brief history. If you don’t want to listen to the ramblings of an old man, skip down to the Input/Output section.
Back in prehistoric times, May 30th, 2002 to be precise, I was working on Puzzle Pirates with my
friend Walter (among others), and he turned me on to keeping track of completed tasks in a
log-formatted text file. I don’t recall if he had heard of the technique from someone else or
originated it, but it seemed like a good idea, and thus began the did.txt era of my PIM journey.
did.txt
While the original suggestion was to keep track of completed work tasks, it took me all of 24 hours
to expand the idea to keeping track of everything I did, as evidenced by the first two entries in
my oldest did.txt file:
* 05/30/2002
- Worked on sea lanes (geometry thinky fiddly)
- Participated in alpha planning meeting
* 05/31/2002
- Debugging lane display
- Log revamp
- Challenge dialog design discussion
- Dinner party at Isobel's
- Antics afterwards at Tom's and StudioZ
Within 48 hours, the seeds of some additional PIM ideas were planted, specifically keeping track of books that I read, movies that I watched, games that I played, etc.
* 06/01/2002
- Installed Afterburner in GameBoy
- Worked on assigning lanes to vessels to avoid collision
- More challenge dialog discussion with Ray
- Started "The Game Players of Titan"
- Muni/BART adventure
- Saw "13 Conversations About One Thing"
Things were fairly free-form during this era. Just get it all recorded and sort it out later. But the free-wheeling, devil-may-care days of youth eventually ossified into more rigid policies and procedures.
Jikan
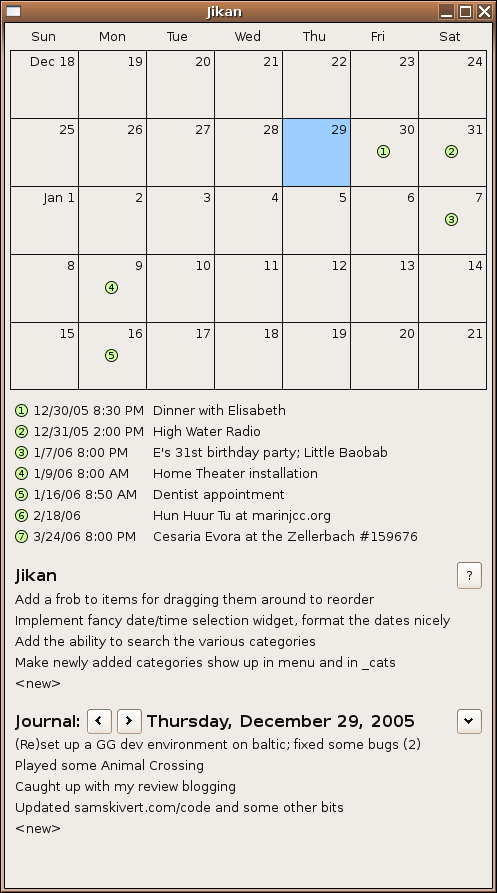
My next incarnation began with a code commit on May 22, 2005. I created a desktop tool (written in Java and SWT) that combined my “did” journal with a calendar, and threw in categorized todo lists to boot: Jikan.
Jikan served my modest PIM needs for a good many years. It evolved to include Google Calendar syncing, and survived many rounds of compulsive UI tweaking. I later removed the todo list support and focused it on just upcoming calendar events and a journal, a “simplification” process which we’ll see repeated again in a later turn of the wheel.
A few things motivated the end of the Jikan era and the beginning of the next. One was that with the introduction of the iPhone in 2007, I started to lament not having access to my data when out and about. Another was that I started a graduate program in late 2009 and my personal data tracking needs expanded substantially. Thus the stage was set for another era-changing code commit on October 28, 2010: the inauguration of Spare Cortex, a web based PIM/wiki hybrid.
Spare Cortex
Spare Cortex sliced and diced and even made Julienne fries. I went a little crazy making it into a proper tool usable by people other than myself, with a live demo site, helpful tutorials and even a manifesto explaining its design principles.
I used Spare Cortex to keep track of design/research notes and task lists for my myriad projects, but I also began keeping explicit track of movies/book/games that I wanted to see/read/play instead of just logging those things after the fact. I was particularly enamored of the ability to composite a “dashboard” page with all the myriad lists I was using to keep track of things:
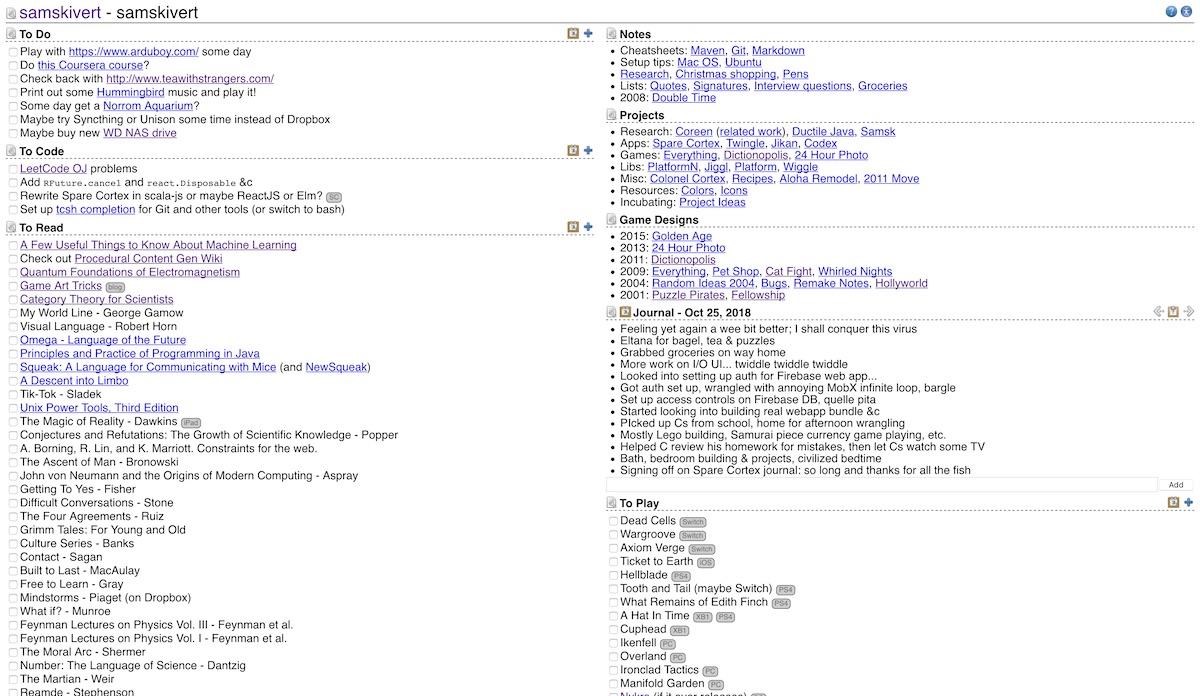
I also had “To See”, “To Listen”, and “To Eat” down below the fold. Such lists, so organize.
Spare Cortex has served me well for the last eight years, but times they keep a changin'. Once again, a variety of motivations combined to push me over the hump of building yet another tool. SC was built before the era of readily available responsive CSS frameworks, so it works well on desktop and is small and fiddly on mobile. SC uses a GWT frontend and a Scala servlet backend, deployed to Google App Engine. It is/was used so infrequently (by myself and the occasional random person on and off over the years) that App Engine would shut down the VM hosting the app. Thus when I went to use it, quite often it would take 15 to 20 seconds for it to spin up a VM+JVM and get to serving the first request.
Using GWT was also a questionable idea in the first place. In 2006, when I first started using GWT (for Whirled), the state of building complex webapps in JavaScript was terrible, so transpiling from Java was not the craziest idea in the world. But by 2010 I should have been looking to the (dystopian) future instead of sticking with an increasingly idiosyncratic evolutionary dead end. It became more and more annoying to make improvements to SC over the years, so I stopped doing so.
The biggest motivation was again a desire to simplify. I hadn’t been tracking new project information on SC for a couple of years. For my most recent big project I decided to try Bear, a native macOS/iOS note taking app and it’s working pretty well. I long ago synced my Google Calendar with my Mac & phone and have been using native calendar apps for that. I tend to use the Reminders app for simple todo stuff, because I can say “Hey Siri, remind me to X”. The main thing I was still using SC for was my journal, and tracking media.
Thus, I decided that I should build a streamlined app for these purposes, and maybe kill a few other birds along the way: make it more mobile friendly, build it using modern tools, etc. Thus, via a commit on October 16, 2018, was ushered in the new Input/Output era.
Input/Output
I/O is a mobile-friendly webapp designed specifically for tracking media (input) and a journal (output). In SC, I only had a text field and hashtags, so I’d use consistent text formatting to track things like the author of a book or director of a film and who recommended it to me, and use tags to track whether it was a film or video, or book or academic paper, etc. With I/O all of this metadata is made explicit.
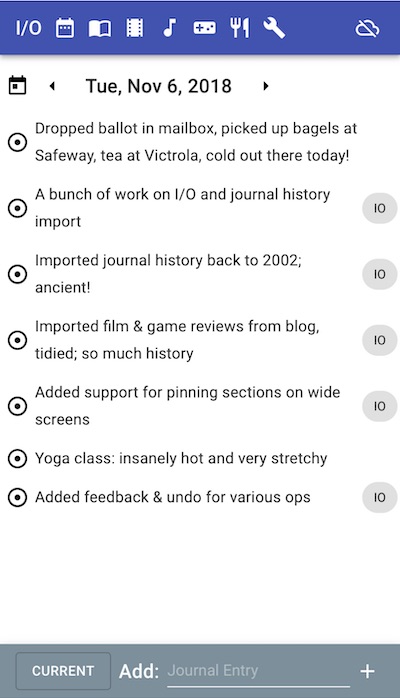
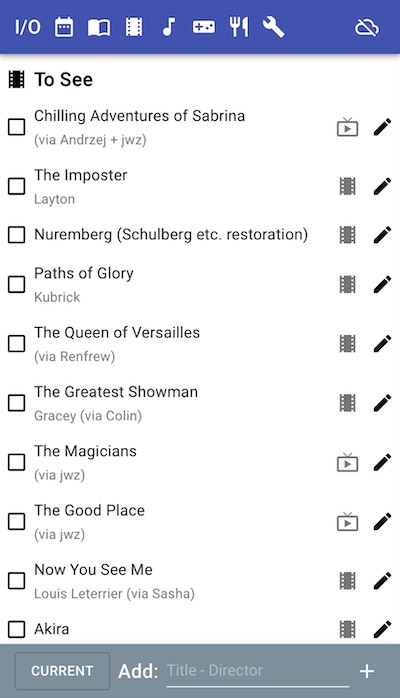
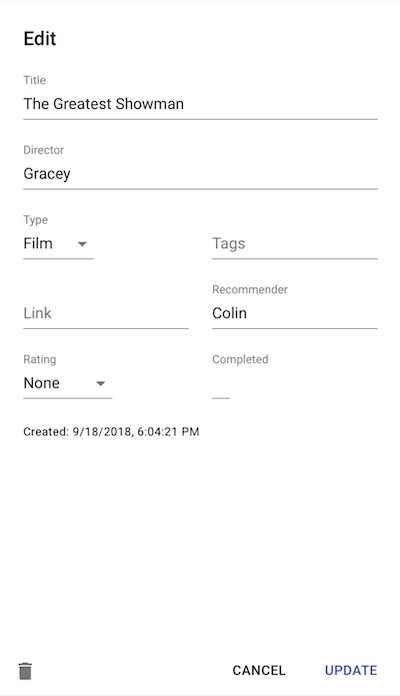
I/O is written in TypeScript using React, material-ui and MobX. It is completely serverless, relying entirely on the (very nice) Cloud Firestore for data storage, Firebase auth for authentication, and Firebase hosting to host the HTML. The only thing that presently costs me any money is the $14 a year for the custom domain. If other people actually use I/O, I may end up having to cough up a few bucks a month in usage fees, but the inevitable ego boost will make it more than worthwhile.
I have uncountably many bad things to say about JavaScript, TypeScript, HTML, CSS, and the entire web ecosystem they swirl around in — like turds in a giant clogged toilet bowl. But, it is truly amazing that I can effortlessly leverage an astonishingly powerful cloud infrastructure: a flexible, scalable, reactive data store (with built-in offline support and syncing), versioned storage of app assets with easy rollback, turn-key handling of custom domains including registration and automatic management of SSL certs, absurdly simple to integrate support for a dozen OAuth providers plus out of the box support for custom account registration for my app that follows (for the most part) current best practices UX and security-wise.
Those are just the things I happened to need for this fairly simple app. The list goes on and on: analytics, blob storage, monitoring, A/B testing, queues, server to client messaging. And all of this is had for free at my usage levels, and beyond that, for eminently reasonable prices that literally scale up at the granularity of HTTP requests and datastore reads and writes.
When this PIM obsession started back in 2002, my personal website and random projects were hosted on a server sitting on a rack in my living room (seriously), talking to the internet via my slow, expensive ISDN connection (OK, maybe it was DSL by then, but it was still slow and expensive). For the (massively multiplayer online) game we were building, I had to build servers from (expensive) parts, install OSes on them, drive them down to the colo and stick them on racks, maintain the OSes, replace hardware when it broke, etc. And this was a big improvement over things back in 1996 when we were starting an Internet company and colos were barely even a thing.
{kind=link}
I just wish the awesome power of this fully operational cloud battleship did not have to be accessed through the appalling historical accidents that are HTML, CSS and JavaScript. I seriously spent 25x as much time fucking around trying to get CSS to do what I wanted than I did wiring up the logic and data storage parts of the app. That’s both a testament to how awesome Cloud Firestore is and how shitty JavaScript, HTML and CSS are. Who knew that we’d be able to put people on the moon no problem, but building the user interface was going to take 90% of the budget?
Anyway, back to I/O. It also supports better history viewing than I ever managed to wire up in SC: annual history views for the journal (because they get kinda lengthy and I didn’t feel like sacrificing any more blood and sweat to the UI gods to get infinite scrolling working) and full history views for media. Including searching/filtering:

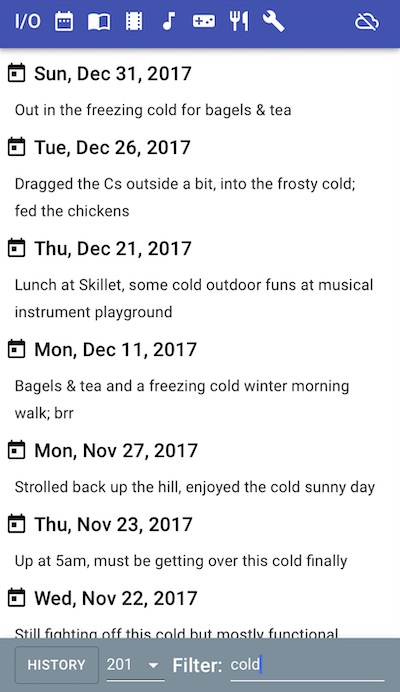
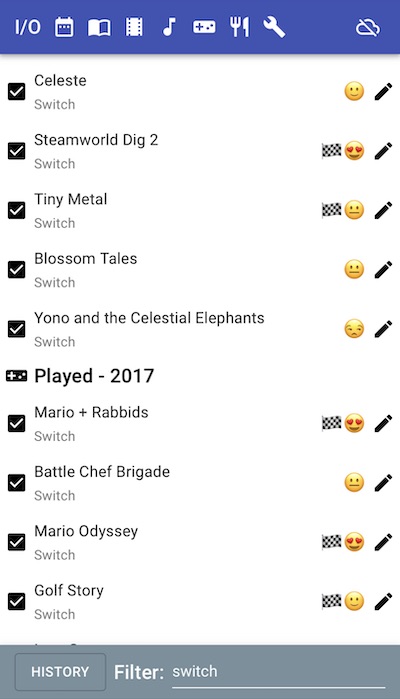
This is pretty awesome when you’re a crazy person like me and migrate sixteen years of journal data and twenty years of media logging/reviews into your powerful new PIM app and then spend nostalgic hours gazing around your own historical navel.
One complaint I can register with Cloud Firestore is that it has no support for full text search. Google, the company who built a trillion dollar empire on being good at full text search, has a “solution” page for full text search in Cloud Firestore that literally tells you to integrate some third-party service into your app. Hey left hand, you should really check out what right hand is doing. It’s pretty amazing.
Since I/O doesn’t really manage gargantuan quantities of data, I work around the lack of full text search support by just loading everything up and doing the search on the client. The journal can only be searched year by year, but the filter/query stays in effect and you can just flip through the years to find what you’re looking for. It could be better, but I’ll be damned if I’m going to wire up cloud functions to ship app data off to some third party indexing service. Christ, someone call Rube Goldberg.
On the other hand, as I mentioned above, Cloud Firestore is fully reactive. You can subscribe to documents (rows) and queries and get notifications when data referenced thereby is changed. I combined this with the reactive plumbing provided by MobX and wired it into the React UI, such that I can write code like this:
function boolEditor (label :string, prop :IObservableValue<boolean>, cells :UI.GridSize = 6) {
const check = <UI.Checkbox checked={prop.get()} onChange={ev => prop.set(ev.target.checked)} />
return <UI.Grid key={label} item xs={cells}>
<UI.FormControlLabel control={check} label={label} />
</UI.Grid>
}
which creates a checkbox for a React UI, such that when the value of that checkbox changes, a boolean-valued property of a persistent document is automatically updated on servers in Google’s data center. Moreover any other instance of the app viewing this particular boolean value will automatically update its UI because the reactivity is plumbed all the way through from cloud-based datastore, through reactive datastore inside the app, up into the reactive UI.
To be fair, I often insert extra layers of blah blah into the UI code because you don’t want to be sending every keystroke-initiated change back to the server immediately, but rather to commit changes when the user indicates that they’re done. But all of that fits nicely into this reactive abstraction without a bunch of additonal manual plumbing.
This part of the experience was far from “out of the box”, and required a whole lot of swearing at TypeScript and MobX, and even a little swearing at the Cloud Firestore JS API. But once it was all wired up, I was truly living the dream. When I eventually finish my rethink programming project, I will write my own Cloud Firestore client library and have a programmatic interface to this awesome cloud battleship that is worthy of the massive power it provides.
One last screenshot of I/O. I went for a “mobile first” approach to the UI this time, as evidenced by the use of Material UI and the fact that all the screenshots look like they were taken on a phone (in fact taken on the iOS Simulator because that was easier). But I still want my “personal information dashboard” open on my desktop computer as well. So I added a way to “pin” categories open when things are displayed on a larger screen:
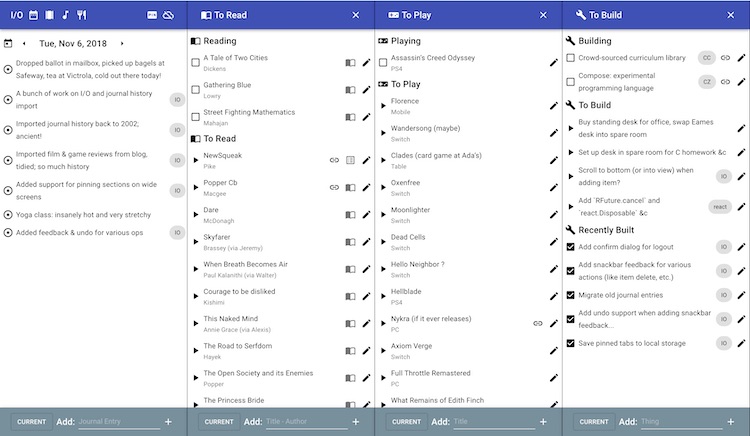
It’s not actually that cumbersome to flip to the appropriate tab as needed, but it felt silly to waste all that horizontal space on a desktop, and I just like seeing big, information dense displays. Maybe I’ll keep a window open on my 24" monitor with all the tabs pinned, yar!
Another improvement over SC that I’m excited about, which you can see on the To Read and To Build tabs is tracking of “in progress” media/projects. For things like books, I have historically tended to start reading a book and then restrict myself to that book only until it was done or I abandoned it. And I very rarely abandoned books. Instead I would just never feel like reading them and go weeks or months reading about 1/10th as much as I normally do. Not great! I recently read about a different philosophy which was to have half a dozen books going all the time. That way when you feel like reading something, there’s a pretty good chance that at least one of the books sounds appealing, and you end up maintaining a high level of “time spent reading”.
Now I can keep track of what I have in progress, and bounce back and forth more easily. Maybe I’ll also benefit from this treatment of programming projects. I’m already pretty good at starting and neglecting those, but maybe if I have a list of all of them in one place, the neglected ones will get more attention.
I also track which books I “abandon” and which games I “complete” (since abandoning books is the uncommon case, and – for me anyway – completing games is also the uncommon case). Moar data for the meaningless statistics displays I will eventually add now that I have all this juicy metadata about my behavior.
That’s probably enough about I/O for now. If you like to obsess about your own input and output as
much as I do, feel free to give it a try. I even registered a fancy .app domain:
inputoutput.app. The source code is also on Github for the curious.
The Future
The did.txt era lasted three years, the Jikan era lasted five years, the Spare Cortex era lasted
eight years. Perhaps this is another place in nature where the Fibbonaci sequence arises naturally,
and the I/O era will last thirteen years. If so, that will leave a lot of time for tweaking and
refinement.
I’m already contemplating building a native iOS client, both because it would be fun to use the Cloud Firestore APIs in conjunction with a less appalling language ecosystem and because I really want to be able to say “Hey Siri, add (book) to my reading list” and have the necessary magic happen. Tragically, that particular platform feature has not yet come to webapps, and it will probably be thirteen years before some half-assed, buggily implemented, approximation of it grinds its way through the standards bodies and achieves unreliable browser support.
More likely I will use this as an excuse to finally try out Flutter, which has been on my list of things to play with since it was called Sky and required compiling half of Fuschia to even try out.
Anyhow, onward into this turn of the wheel!